Fleet Active Learning: A Submodular Maximization Approach
posted on February 25, 2024
By Oguzhan A.
Fleet Active Learning with Submodular Maximization
Motivation
The recent success and popularity of machine learning (ML) models provide unique opportunities for developing ML models. Today, we can collect data from previously unseen diverse environments, which can be used to increase the robustness and overall performance of these ML models. This is especially true in the context of autonomous vehicles (AVs), where the collection and processing of diverse and informative data are pivotal for enhancing ML models. These models, integral to the vehicles’ perception, prediction, and planning capabilities, thrive on varied datasets that enable them to generalize across different environments. However, the current methods for data collection are not efficient enough to utilize the full potential of the data collection. Addressing this gap, our novel “Fleet Active Learning” framework emerges as a solution to three pivotal challenges:
- How do we efficiently gather diverse and informative data in a fleet of robots?
- How can we scale data collection methods to accommodate large fleets without overwhelming bandwidth and storage capacities?
- How do we optimize the data collection process to enhance the performance of ML models?
The Challenge of Redundancy in Data Collection
When AVs operate independently to collect data, there is a significant risk of redundancy. Multiple vehicles may gather similar data points, which doesn’t add value to the collected dataset. This redundancy not only wastes resources but also fails to enrich the models’ learning with new, diverse information. Given constraints like bandwidth and computational resources, it is crucial for these vehicles to prioritize the collection of unique and informative data points that can substantially improve their ML models’ performance.
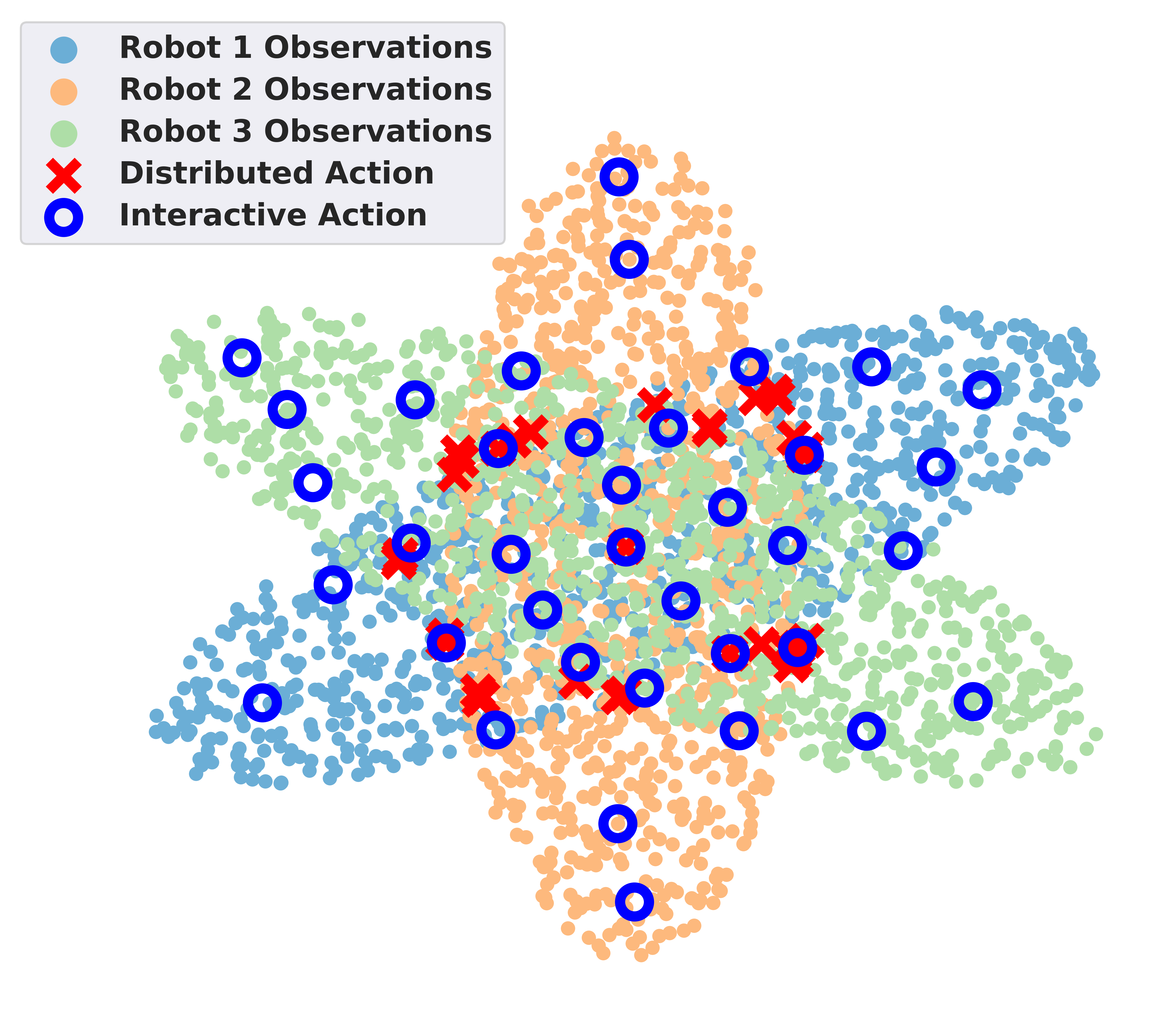
In the figure above, we show a toy example of why redundancy is a huge problem in data collection in a fleet setting. Here the robots observe 3 different data distributions that are mapped into a 2D space. The red crosses represent the data selected by each robot independently in a distributed manner, while the blue circles represent the data selected by robots interactively. Compared to the distributed approach, the interactive approach selects a more diverse set of data points, covering a broader range of scenarios.
An Interactive Solution through Submodular Maximization
Our work addresses these challenges by introducing a fleet active learning framework that leverages the submodular maximization approach. This approach is adept at handling situations where the value of adding data points diminishes over time - a concept known as diminishing returns. In essence, the method prioritizes data points that offer the most significant incremental value, ensuring that the selected dataset is not just large but also highly informative.
How Fleet Active Learning Works
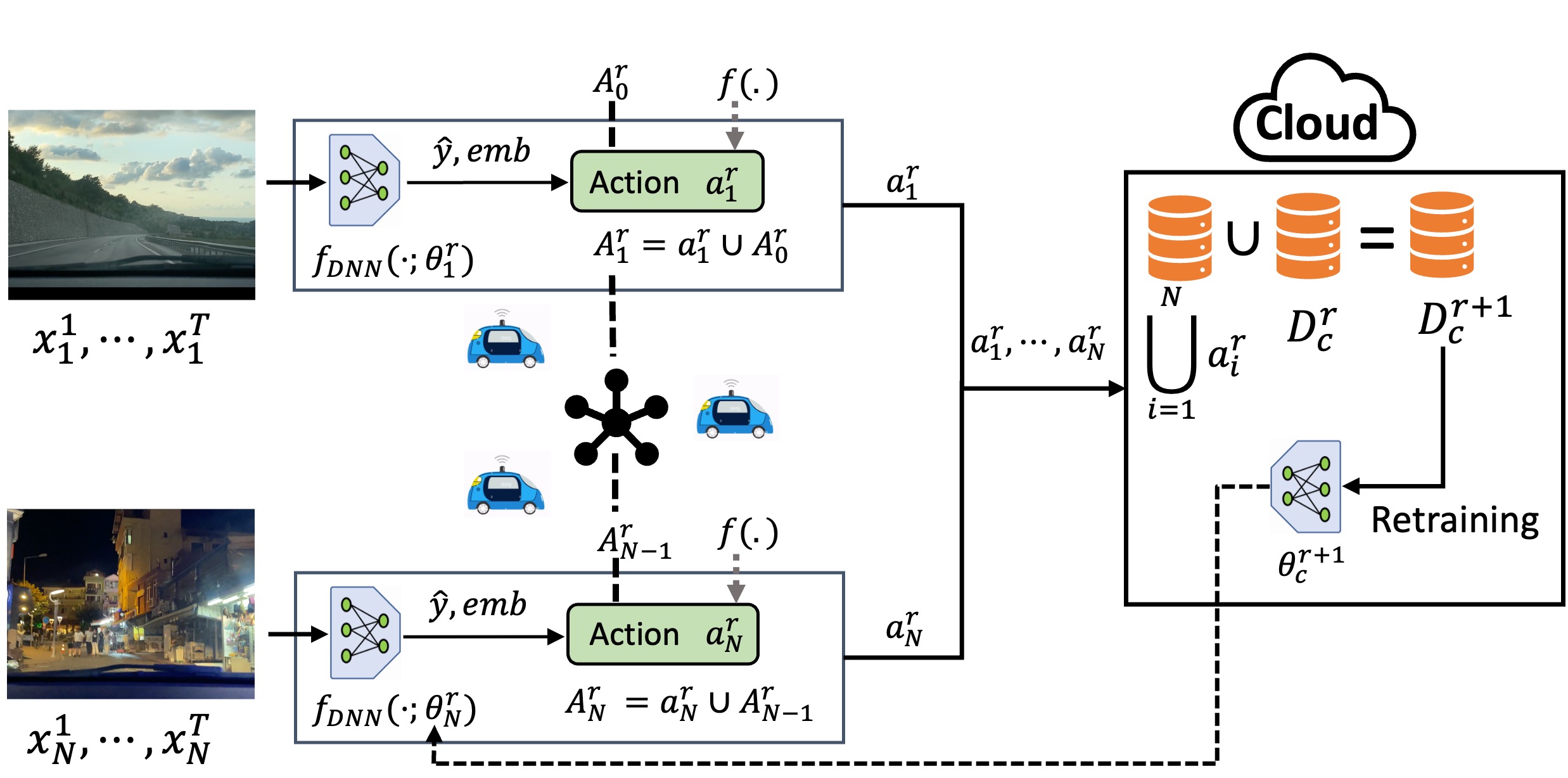
Each robot in the fleet observes a stream of data points and processes them using its neural network to obtain predictions and embeddings. These embeddings and predictions are then used to select an action to sample data points, maximizing a submodular function while considering the previous robots’ actions. The aggregated action is passed to the next robot, repeating the process until all robots have taken an action. At the end of each round, the actions are shared with the cloud, which labels the newly acquired data points and updates the training dataset with the new data points. The model is retrained with the new dataset, and the updated model weights are shared with all robots, which update their model parameters accordingly.
Experimental Results
We show that our decentralized interactive approach is able to achieve superior performance compared to the traditional distributed approach and achieves the same performance as an upper-bound “Centralized” approach. Our FAL framework achieved up to a 25% increase in classification accuracy compared to a completely distributed baseline.
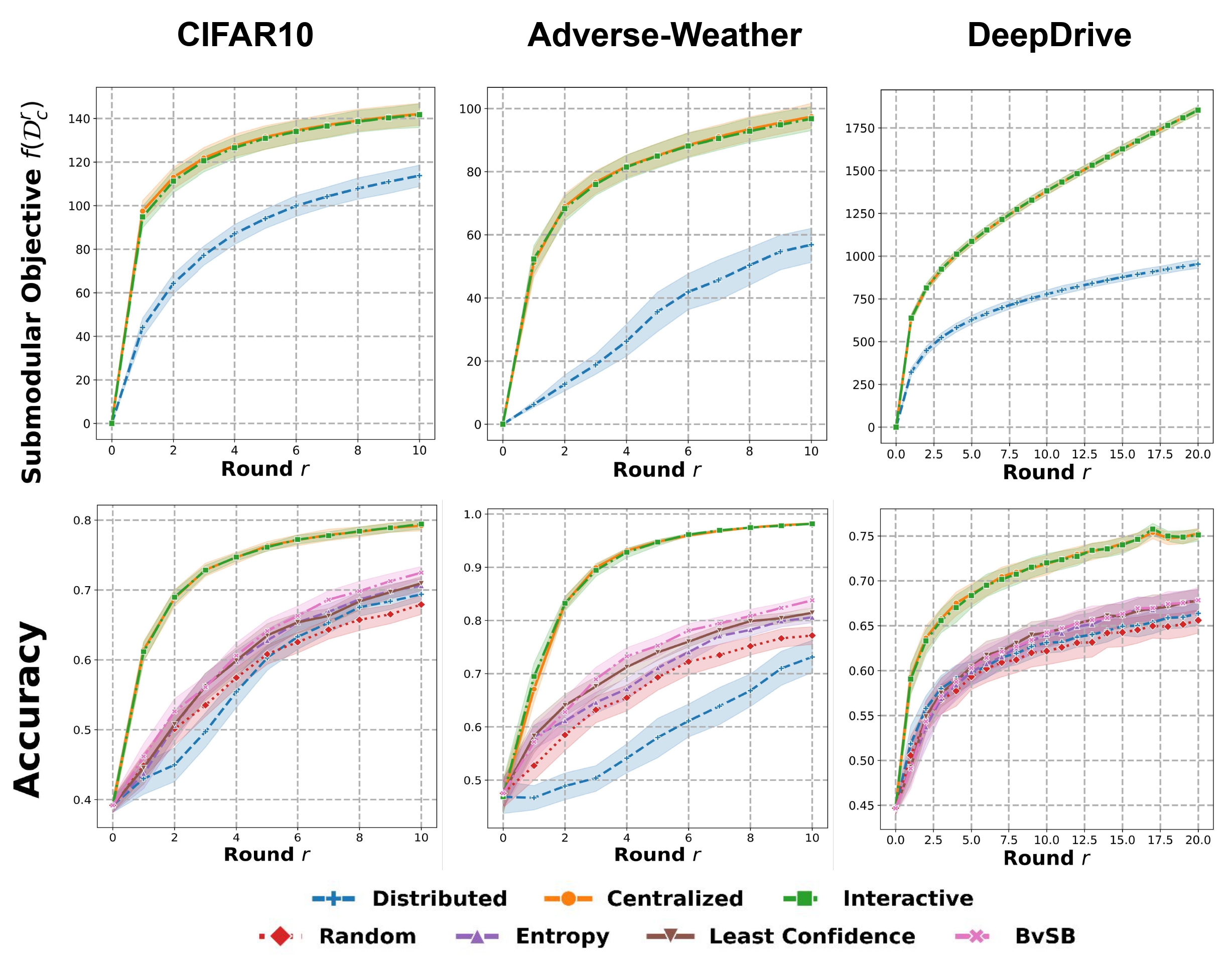
In the figure above, each column represents a different dataset. Row 1 shows the submodular objective of the cloud dataset across the rounds. Both the Centralized and Interactive policies achieve similar objectives, while the Distributed fails to reach the same level of performance. Row 2 presents the accuracy of the retrained neural networks using the accumulated dataset in each round r. The accuracy plots exhibit a similar trend as the submodular objective, with the Interactive and Centralized policies consistently outperforming other benchmark policies.
Conclusion
Our work “Fleet Active Learning: A Submodular Maximization Approach” introduces a framework for enhancing the capabilities of AVs through smarter data collection methods. By adopting the FAL framework, fleets of autonomous vehicles can efficiently gather diverse data essential for training robust ML models, enabling the development of more robust and better-performing autonomous vehicles.