Safe Networked Robotics with Probabilistic Verification
posted on July 7, 2024
By Sai Shankar Narasimhan.
Motivation
Recently, an increasing number of robotic applications have adopted remote assistance through teleoperation, ranging from remote manipulation for surgery to emergency takeover of autonomous vehicles. Teleoperation is even used to control food delivery robots from command centers hundreds of miles away. What has contributed to this trend?
We identify the following two crucial reasons:
- Mobile robots are constrained by their onboard computing power and cannot run powerful deep neural networks (DNNs) for perception and control tasks. Hence, it is preferred to offload sensor observations to a remote server via wireless networks, where these powerful DNNs can be run.
- Autonomous robots cannot handle all possible edge cases. While encountering a new scenario (out of the training distribution), it is necessary to have a human-in-the-loop to take over control.
Though teleoperation has a lot of potential benefits, there are practical concerns that need to be addressed. For example, while using public communication networks, stochastic communication delays could potentially lead to the violation of key safety properties.
Therefore, in this work, we ask the following key question: How do we ensure safe networked control over wireless networks with stochastic communication delays? This blog will briefly explain our proposed solution and experimental results, including a real-world demonstration of safe networked control using F1/10th cars while transmitting sensor data through our university’s public Wi-Fi network.
To motivate the requirements of a safe networked control system, let us take a look at our proposed solution, shown in the image below.
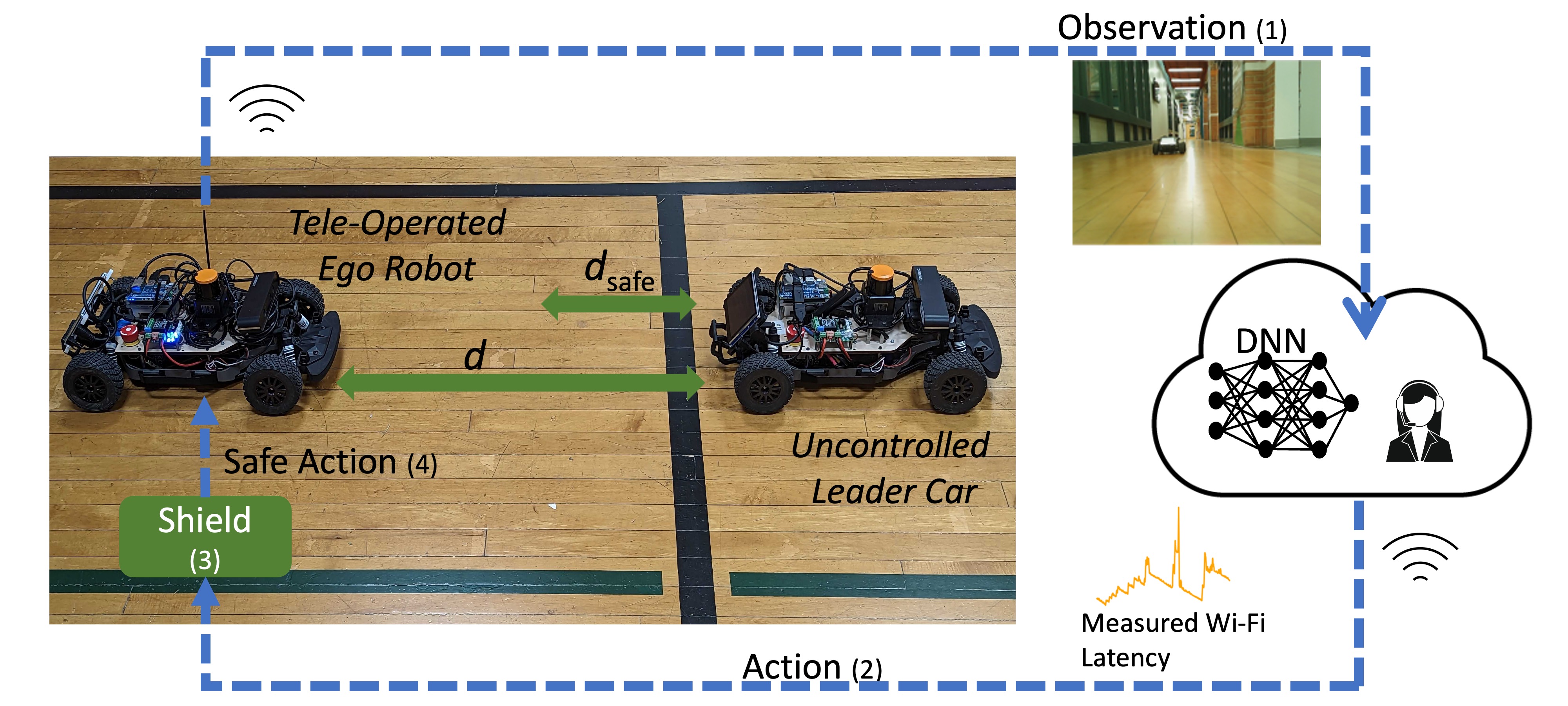
We implemented our proposed solution on a real-world leader-follower setup. The leader is uncontrolled and can exhibit stochastic motion. The follower is controlled remotely by a teleoperator or using a DNN. The sensor observations are transmitted to the remote server or cloud through a public Wi-Fi connection (step 1). The teleoperator or the DNN generates a control command, which is transmitted back to the follower (step 2). We propose a shield that restricts or modifies an unsafe control command based on its communication delay magnitude (step 3). Finally, the follower executes the “safe” control command (step 4).
What do we need to achieve safe networked control?
To develop a safe networked control system, as shown in the figure above, we require the following:
- Ability to accurately model the interaction between the mobile robot and the environment in the presence of delay. Previous works make assumptions about the delay transitions, such as the delay is constant and non-decreasing. However, we end up with a very conservative model of the interaction with these assumptions.
- Ability to trade off safety for efficiency according to the user's needs. This is important as we are dealing with a system with stochastic delays. Optimizing for absolute safety would translate to optimizing for the worst-case delay, which might occur very rarely.
Modeling the interaction between the robot and the environment in the presence of delay
Typically, Markov Decision Processes (MDPs) are used to model the interaction between a robot and its environment. To extend MDPs to the networked control setting, we developed Delayed Communication Markov Decision Processes (DC-MDP) without any conservative assumptions about the delay transitions.
Our key intuition is that by augmenting the states of the basic MDP (model of the interaction in the absence of delay) with fixed-length action buffers containing the number of actions corresponding to the actual delay, we can represent system states with arbitrary delays. Additionally, given the delay transition probability, we can accurately obtain the transition probability between the system states for two consecutive time steps with arbitrary delays. We refer the readers to Section 5.A of the manuscript for further details.
Ensuring Safety
We use Linear Temporal Logic (LTL) to formally represent our desired notion of safety for the system as safety specifications. We refer the readers to Section 3 of our manuscript for a detailed discussion on LTL and safety specifications. Given an MDP and a safety specification, the preferred approach to ensure safety is shielding. For any given system state, shielding allows those actions to be executed for which the maximum safety probability is 1.0. This ensures that the system is safe. Additionally, executing shielded actions ensures that the system always remains in a safe state. The literature on shielding is vast and will not be covered in this blog.
Achieving Safety-Efficiency Trade-Off
With the DC-MDP and the shield for the required safety specification, the naive solution is to apply shielding to the DC-MDP and ensure absolute safety for the networked control system. However, we note that this adversely affects the system’s task performance. This is attributed to the fact that ensuring absolute safety always considers the worst-case scenario, which is the maximum delay case. However, the maximum delay case is a very rare occurrence. Hence, we propose ε-shields that can trade off safety for task efficiency. We refer the reader to Algorithm 1 in our manuscript for the definition and synthesis of ε-shields. Intuitively, ε is a value between 0 and 1, and increasing ε increases safety. Our proposed ε-shields can guarantee any desired safety probability. This flexibility allows the user to trade off safety to achieve higher task efficiency.
Experimental Results
We test our approach on the following two simulation environments:
- Leader-Follower Simulation Setup: The follower should get as close as possible to the leader while maintaining a safe distance. The state information contains the relative distance and the relative velocity.
- Grid World Simulation Setup: The robot has to traverse an 8x8 grid from start to goal without colliding with an adversary. An episode is declared a win if the robot reaches the goal, a loss if the robot collides with the obstacle, and a tie if the robot does not reach the goal.
Now, we will describe the two main takeaways from our experiments with these two simulation environments.
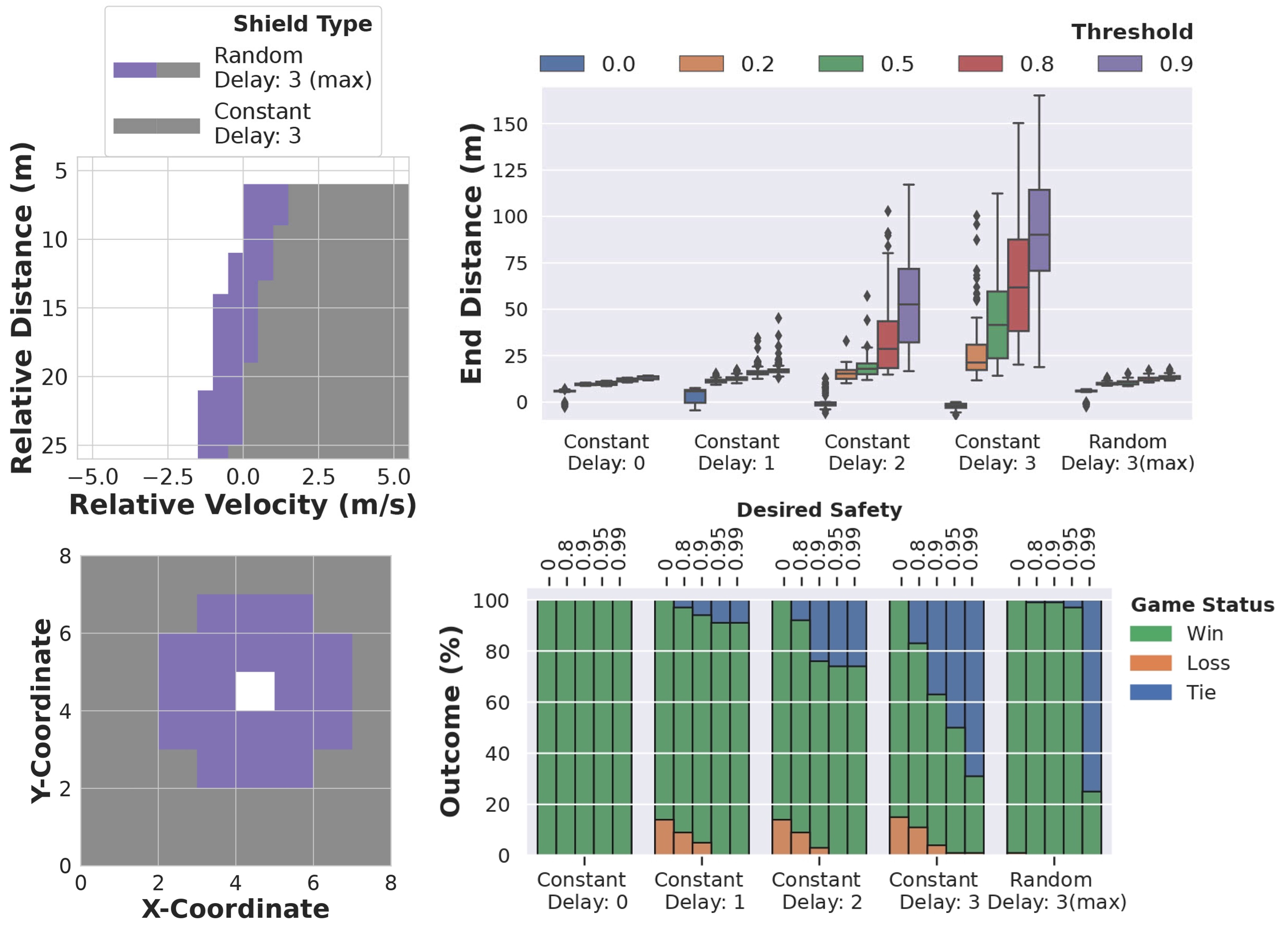
- The set of safe states expands for the DC-MDP. Since the DC-MDP accurately models the robot-environment interaction without any conservative assumptions on the delay transitions, we observe more safe states when compared to the previous models with conservative assumptions on delay transitions, such as constant maximum delays. This directly translates to aggressive robot behavior or higher task efficiency. In the figure shown below, note that for the same value of maximum allowable delay, the set of safe states for DC-MDP (Random Delay) is much larger than that obtained with the constant maximum delay assumption.
- ε-shields trade off safety for efficiency. Our experiments show that we can decrease the value of ε to lower the achievable safety probability, thereby achieving higher robot task efficiency. This is shown by a reduced distance from the leader in the leader-follower environment and an increased number of wins in the grid-world environment.
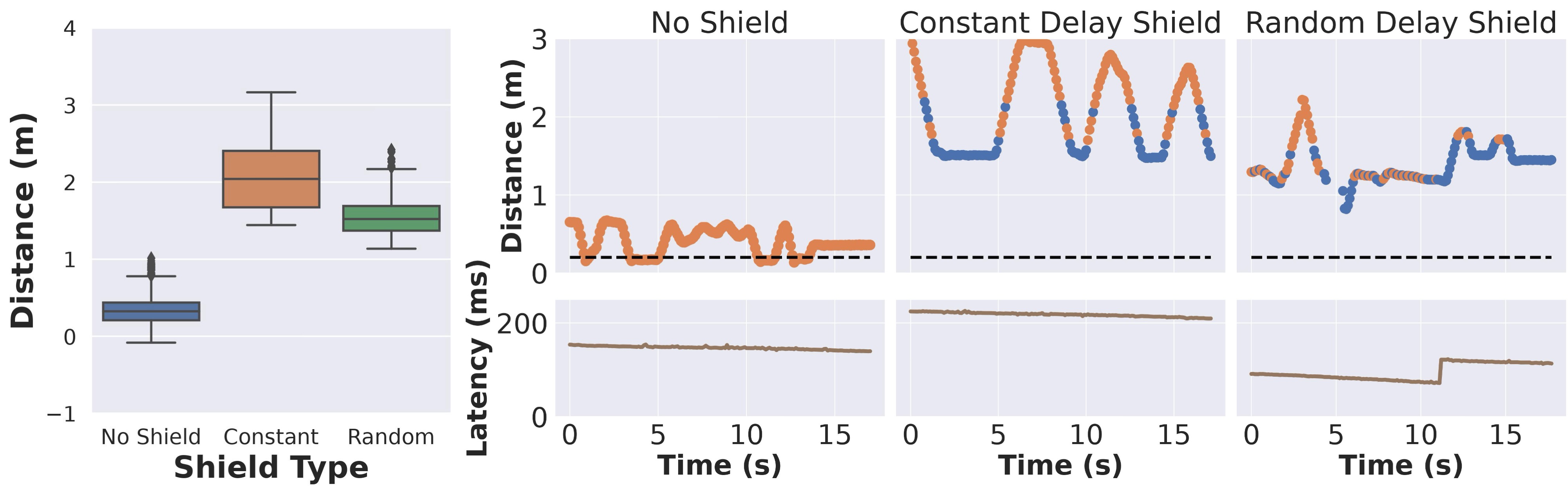
We show similar results with the real-world demonstration (check the figure below). In the absence of shielding, we observe safety violations due to the communication delay while using our university’s public Wi-Fi network for sensor data transmission. Additionally, note that the distance between both cars is lower in the presence of ε-shields (Random Delay), highlighting better task efficiency.
Conclusion
Our work, “Safe Networked Robotics with Probabilistic Verification”, provides a novel approach to ensure safety for networked control systems. Through multiple simulation and real-world experiments, we demonstrate how our approach can gracefully trade off safety for efficiency while dealing with stochastic communication delays.