Exploiting Distribution Constraints for Scalable and Efficient Image Retrieval
posted on April 1, 2025
By Mohammad Omama
Exploiting Distribution Constraints for Scalable and Efficient Image Retrieval
Proceedings of the International Conference on Learning Representations (ICLR)
TLDR: Image Retrieval with Foundation Models: Better, Faster, Distribution-Aware!
Motivation
Image retrieval is pivotal in many real-world applications, from visual place recognition in robotics to personalized recommendations in e-commerce. However, current state-of-the-art (SOTA) image retrieval methods face two significant problems:
-
Scalability Issue: State-of-the-art (SOTA) image retrieval methods train large models separately for each dataset. This is not scalable.
-
Efficiency Issue: SOTA image retrieval methods use large embeddings, and since retrieval speed is directly proportional to embedding size, this is not efficient.
Our research specifically targets these challenges with two crucial questions:
- Q1 (Scalability): Can we enhance the performance of universal off-the-shelf models in an entirely unsupervised way?
- Q2 (Efficiency): Is it possible to design an effective unsupervised dimensionality reduction method that preserves the similarity structure and can adaptively perform well at varying embedding sizes?
Contributions
To tackle the scalability and efficiency challenges, our work introduces the follwoing novel ideas:
-
Autoencoders with Strong Variance Constraints (AE-SVC): Addressing scalability, AE-SVC significantly improves off-the-shelf foundation model embeddings through three rigorously enforced constraints: orthogonality, mean-centering, and unit variance in the latent space. We both empirically demonstrate and mathematically validate that these constraints adjust the distribution of cosine similarity, making embeddings more discriminative.
-
Single Shot Similarity Space Distillation ((SS)2 D): To tackle efficiency, (SS)2 D provides dimensionality reduction that preserves similarity structures and further allows embeddings to adaptively scale without retraining. This enables smaller segments of the embedding to retain high retrieval performance, significantly speeding up retrieval.
Methodology
Our proposed approach follows a two-step pipeline:
- AE-SVC first trains an autoencoder with the constraints mentioned to enhance the embeddings from foundation models.
- The improved embeddings from AE-SVC are then distilled using (SS)2D, producing embeddings that are both efficient and adaptive at various sizes.
The training process ensures that the resulting embeddings, even at smaller sizes, preserve similarity relationships, making them highly effective for retrieval tasks.

Impact on Cosine Similarity Distribution
Our AE-SVC method profoundly impacts cosine similarity distributions, significantly reducing their variance. Lower variance in similarity distributions correlates with improved discriminative power as we mathematically prove in our paper. Our method shows remarkable benefits, particularly for general-purpose foundation models like DINO, compared to already optimized dataset-specific models such as Cosplace.
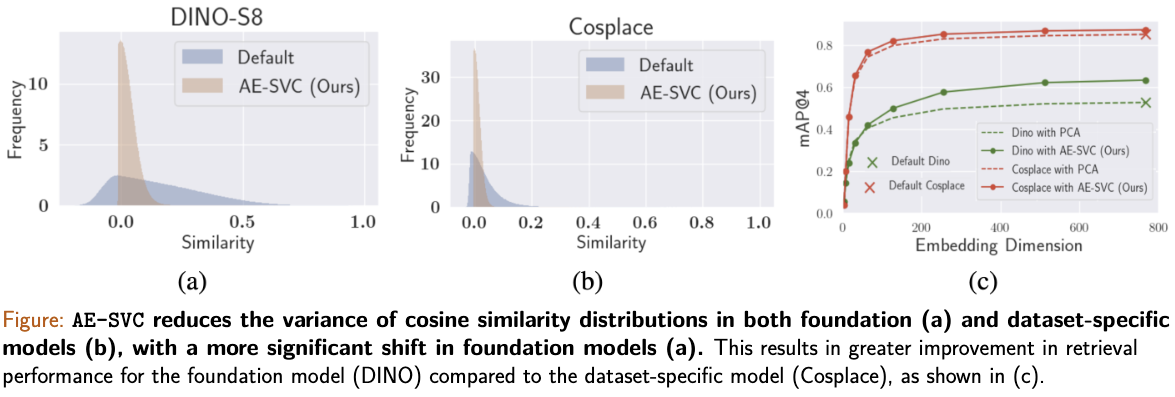
Results
Our experimental validation demonstrates:
- AE-SVC consistently surpasses baseline PCA methods across multiple datasets, offering an average of 15.5% improvement in retrieval performance.
- (SS)2D, building upon AE-SVC, achieves up to a 10% further improvement at smaller embedding sizes, demonstrating superior performance compared to traditional dimensionality reduction methods like VAE and approaches the theoretical upper bound set by SSD.
This advancement represents a significant step towards more practical, scalable, and efficient image retrieval solutions, enhancing both speed and accuracy.
