VIBE: Annotation-Free Video-to-Text Information Bottleneck Evaluation for TL;DR
posted on September 21, 2025
By Po-han
VIBE: Annotation-Free Video-to-Text Information Bottleneck Evaluation for TL;DR
Proceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
TLDR: Annotation-free video summarization evaluation that boosts human decision-making accuracy by up to 61% and cuts response time by 75%!
Project Website | arXiv | Code | Dataset
Motivation
Many real-world tasks still require human oversight: a traffic officer sifting through dashcam footage, or a researcher screening long conference videos. Watching raw video is slow, and existing vision-language models (VLMs) often produce verbose, redundant captions that hinder efficiency. Current video-to-text evaluation methods depend on costly human annotations and ignore whether summaries actually help humans make decisions. We ask:
- Q1 (Annotation-Free): Can we evaluate video summaries without relying on gold-standard human captions?
- Q2 (Task-Aware): Can we measure how much a summary improves human performance on downstream tasks?
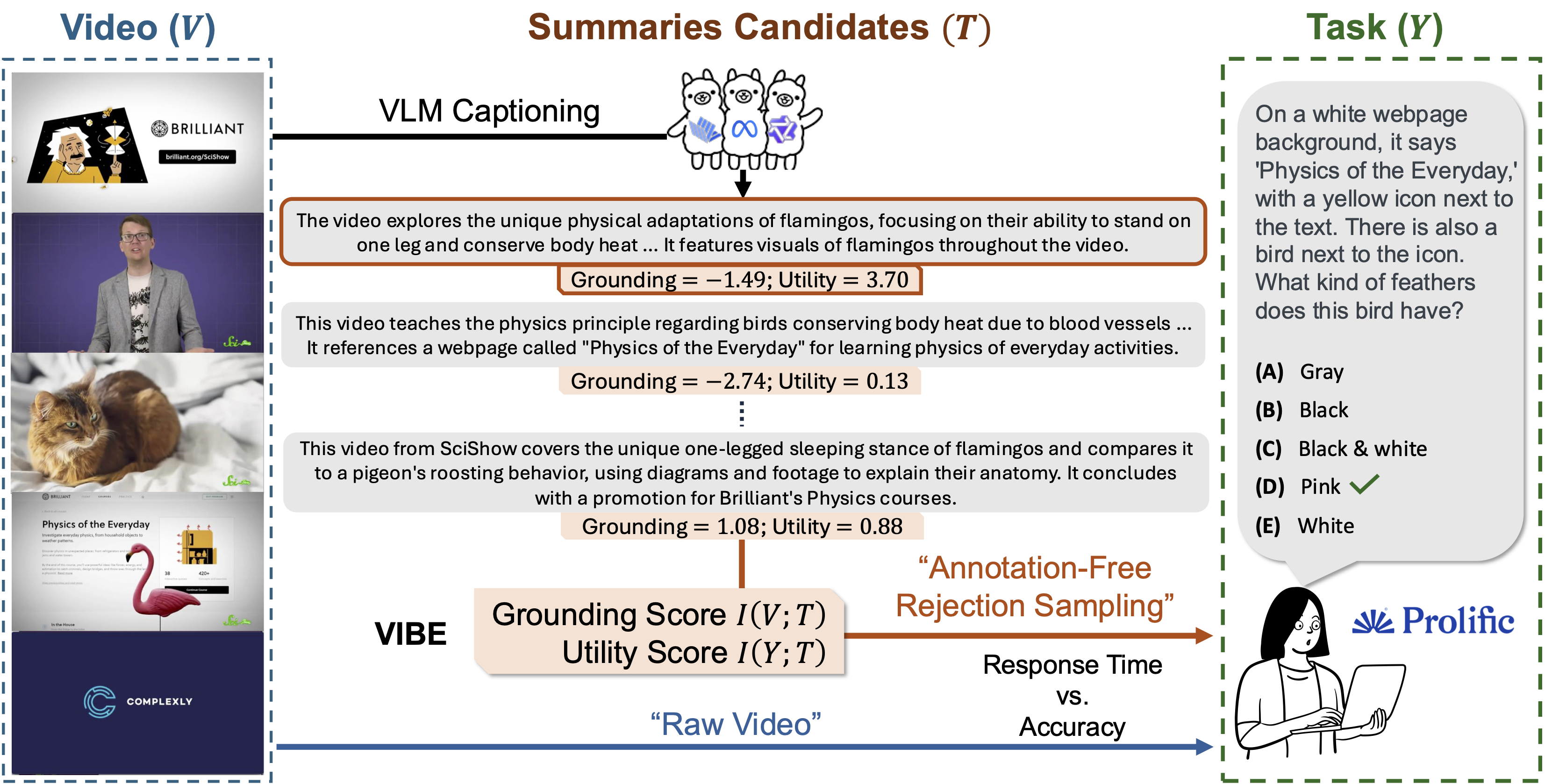
Contributions
We introduce VIBE (Video-to-text Information Bottleneck Evaluation), a novel framework that evaluates and selects VLM summaries without annotations or retraining.
- Grounding Score: Measures how faithfully a summary reflects the video using pointwise mutual information between video and text.
- Utility Score: Measures how informative the summary is for a downstream task.
- Annotation-Free Rejection Sampling: VIBE ranks multiple VLM-generated summaries and selects the one that maximizes grounding and/or utility, supporting efficient human decision-making.
VIBE Framework
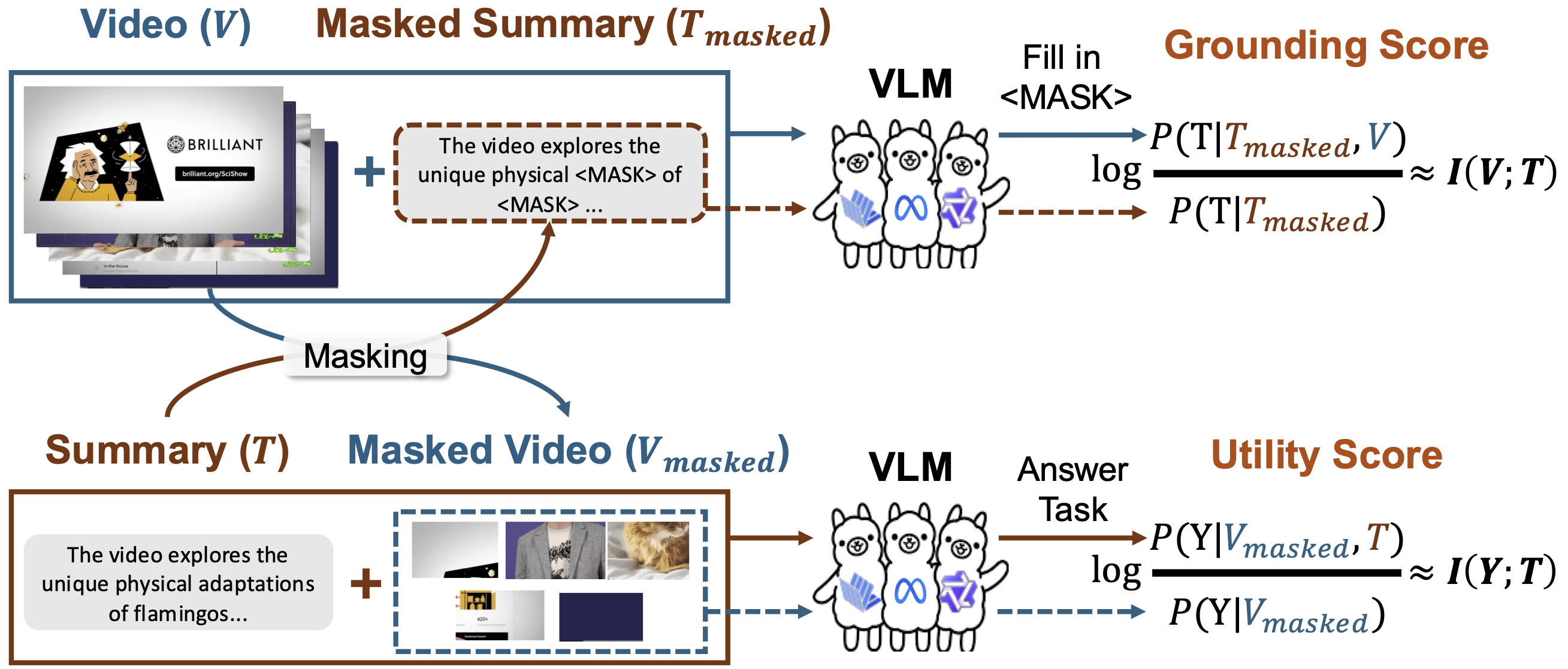
VIBE adapts the information bottleneck principle to video summarization:
- Grounding approximates I(V;T), testing how well the video supports reconstruction of a masked summary.
- Utility approximates I(T;Y), testing how well the summary compensates for missing video information to predict a task label.
By maximizing both, VIBE selects concise, task-relevant summaries—without gold labels or retraining.
Results
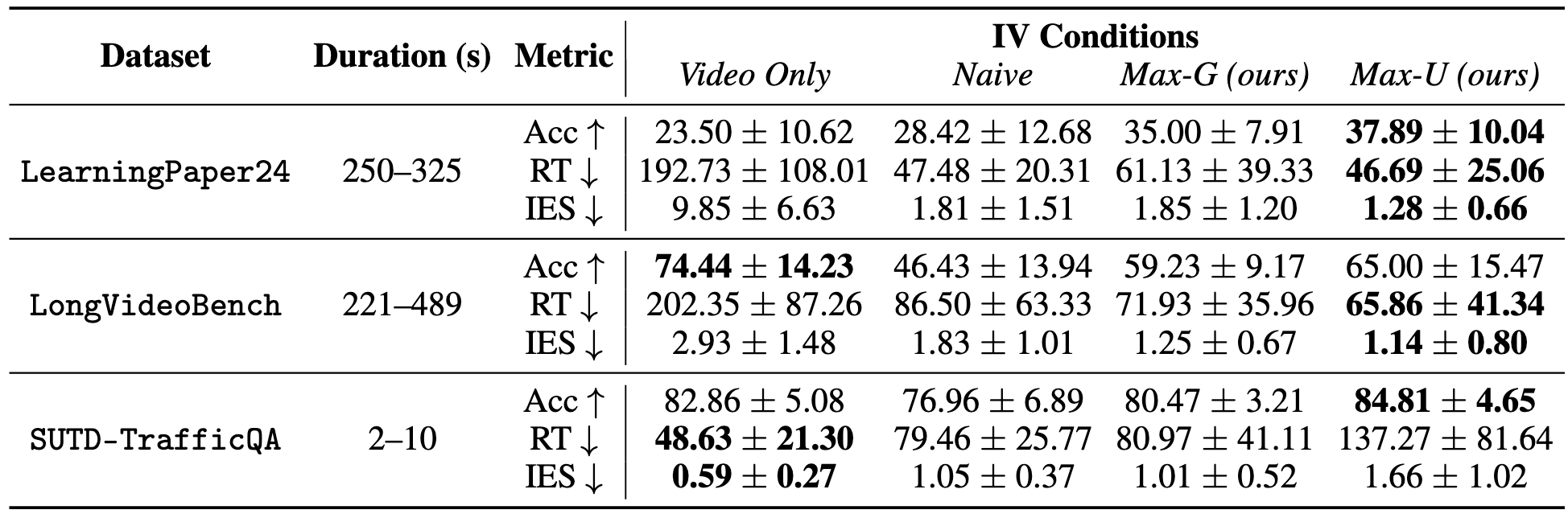
We validate VIBE through user studies with 243 participants across three datasets:
- LearningPaper24 (research talk videos)
- LongVideoBench (long instructional clips)
- SUTD-TrafficQA (short traffic clips)
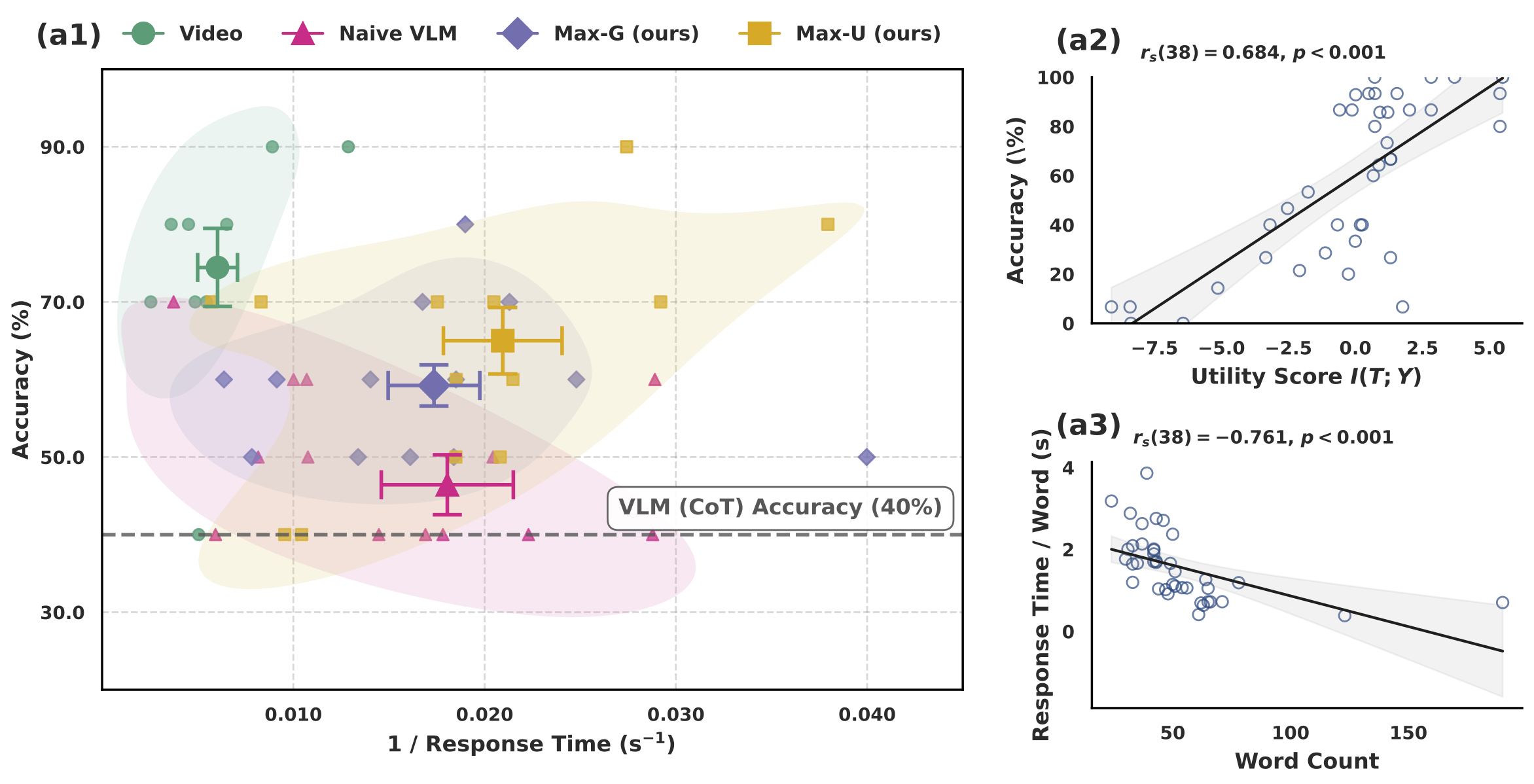
Key findings:
- Accuracy Gains: VIBE-selected summaries boost task accuracy by up to 61.23%.
- Speed Improvements: Response time drops by up to 75.77% compared to raw video.
- Efficiency: VIBE achieves lower inverse efficiency scores (time/accuracy), showing superior speed–accuracy trade-offs.
- Scalability: Grounding works in a fully self-supervised manner, while utility correlates strongly with higher task accuracy.
Impact
VIBE reframes video caption evaluation from a human decision support perspective. Unlike reference-based metrics, it scales to unseen data, works with black-box VLMs, and requires no human annotations. This makes VIBE a practical plug-in for improving video summarization in real-world settings: from scientific video search to public safety monitoring.